The April Eco-Stats Lab (Friday 24th, 2pm, Bioscience level 6) will be on zero inflated data in ecology.
It's very common for ecological data to contain many zeros. To account for this we may need to:
1. Use zero inflated regression models
2. Do absolutely nothing (i.e. fit standard glm's)
In this lab we'll talk about why many zeros may occur in ecology, and the appropriate ways to account for them in your analysis.We will mostly use the pscl package in R.
Many Zeros in Ecology
Your abundance data may look like
this.
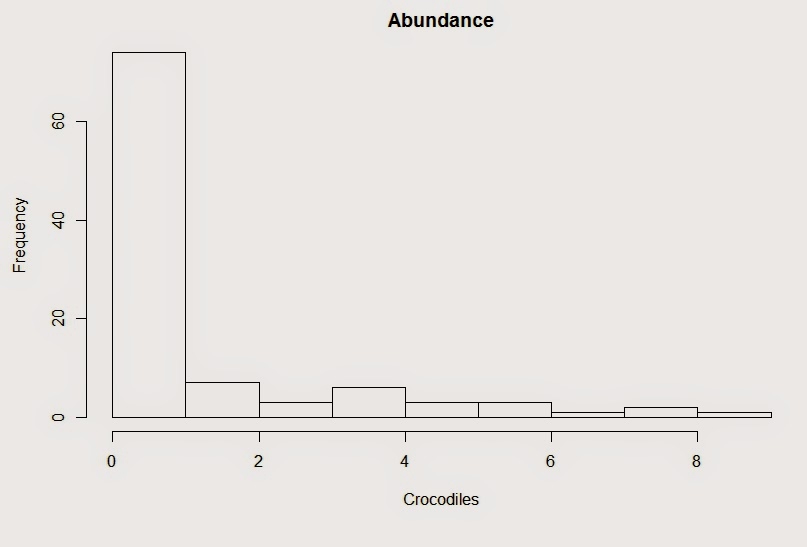
We can see these data have a lot
of zeros, and may be zero inflated. Some possible reasons are
1. There is one process
(ecological variables like climate etc) governing both presence and abundance.
(E.g. species is not abundant in wet whether, and wet whether is
common in the dataset)
2. There are two (possibly
related) processes, one governing presence, the other abundance (E.g. species
can only occur in temperatures above 20°, beyond
this abundance is affected by rainfall and time of day)
Do you need zero inflated models
for your data with many zeros?
Some of the reasons above require
zero inflated models to be fit, but reason 1 does not, and may be a very common
reason for excess zeros, see Warton (2005).
Let's have a look at a simulated
example. I have simulated count data which is exactly Poisson distributed, with
no zero inflation, but with a mean that depends on temperature though this
formula.
λ = exp( 12.4 -4*log(temp) )
The histogram above is of this
dataset I simulated. There are lots of zeros, but I specifically did not
simulate a zero inflated model, just a regular Poisson model with
an explanatory variable. If I look at the raw counts in isolation,
using a histogram, or by applying a test of zero inflation, we would
conclude the data is zero inflated, and we would be wrong.
Let’s go to R and fit some
models, and see what models fit best.
load("Crocs")
library(pscl)
glm.pois=glm(Croc~log(temp),family=poisson,data=Crocs)
zi.pois=zeroinfl(Croc~log(temp) ,data=Crocs)
AIC(glm.pois,zi.pois)
So AIC is lower for the model
with no zero inflation, as expected, since that is the model we simulated from.
We can also look at how many zeros are expected by each of these models, and
how many we have. This is just to convince ourselves we have a sensible model,
it’s not a formal test of anything.
round(c("Obs"
= sum(Crocs$Croc < 1),
"glm.pois" = sum(dpois(0,
fitted(glm.pois))),
"zi.pois" =
sum(predict(zi.pois, type = "prob")[,1])))
Note on AIC
The AIC
is approximate in this setting, and it may favour the more complex model (in
this case the zero inflated model) in some cases where a glm is the better
model, but there’s not much harm in that. There are alternatives, like the
Vuong test (vuong() in pscl) which may work better, or you could try bootstrap
if you’re feeling adventurous.
The Moral of this simulation
Just because your data contains
lots of zeros, does not mean its zero inflated. You should fit models with explanatory
variables with and without zero inflation, and check which model fits best,
using model selection methods (e.g. AIC)
Three complications to zero
inflated models
1. Overdispersion
Ecological data is commonly
overdisprsed (the variance is larger than the mean). We often address this by
using a negative binomial distribution to model data instead of a Poisson
distribution. If you believe you have both zero inflation and overdispersion,
there is an option in pscl to use a zero inflated negative
binomial distribution, This might be a better choice than the zero inflated
Poisson, although you can also use AIC to see which fits best. To use the
negative binomial distribution add dist="negbin" inside the zeroinfl()function.
2. Hurdle models vs zero inflated
models
There are actually two generic
ways to model zero inflation, and they differ in terms of whether they
attribute some of the zeros to the Poisson (negative binomial)
distribution, or whether all the zeros are attributed to a presence/absence
process. The zeroinfl() function is the former type, but you can also try the
latter type using the hurdle() function instead of the zeroinfl(). They tend
to give pretty similar results, and you can test which one is better with
AIC. The hurdle models are a little easier to interpret.
3. Same or
different explanatory variables for presence/absence and counts.
As mentioned above, there are
different reasons for zero inflation. Explanatory variables might
only affect counts, or they may affect both counts and presence/absence,
or different explanatory variables can affect counts than
affect presence/absence. We can fit zero inflated models with all these
scenarios by modifying the formula inside the hurdle()or zeroinfl() function. The
general formula is
Counts ~ count covariates |
presence covariates
e.g. Croc ~ log(temp) | pres
Putting it all together (1+2+3)
hurdle.nb=hurdle(Croc ~ log(temp) | pres
, dist="negbin",data=Crocs)
Real data examples
Example 1: Odontophora in tasmania
library(MASS)
library(mvabund)
library(mvabund)
data(Tasmania)
tas=list(Abund=Tasmania$abund[,47],Trt=Tasmania$treatment)
tas$Abund
glm.nbin=glm.nb(Abund~Trt,data=tas)
hurdle.nbin=hurdle(Abund~Trt|Trt,dist="negbin",data=tas)
zi.nbin=zeroinfl(Abund~Trt|Trt,dist="negbin",data=tas)
AIC(glm.nbin,hurdle.nbin,zi.nbin)
#seems like the glm fits best
#refit with mvabund for better residual
plot
glm.nbin=manyglm(Abund~Trt,data=tas)
plot(glm.nbin)
Example 2 – Published papers
data(bioChemists)
chem.glm <- glm(art ~ ., data =
bioChemists, family = poisson)
chem.zip <- zeroinfl(art ~ . | .,
data = bioChemists)
chem.hurd <- hurdle(art ~ . | .,
data = bioChemists)
AIC(chem.glm, chem.zip,chem.hurd)
vuong(chem.glm, chem.zip) #can only
compare two models
#zero inflated and hurdle models are better for these data
summary(chem.zip)
summary(chem.zip)
Extensions
Zero inflated Mixed models
Look at glmmADMB and MCMCglmm for possible implementations, but these are
not straight forward to implement.
Multivariate zero inflated models
MCMCglmm can do
multivariate also.
Bibliography
Zuur, Alain,
et al. Mixed effects models and extensions in ecology with R. Springer Science & Business Media, 2009.
Warton, David
I. "Many zeros does not mean zero inflation: comparing the goodness‐of‐fit of
parametric models to multivariate abundance data."Environmetrics 16.3 (2005): 275-289.
Martin, Tara
G., et al. "Zero tolerance ecology: improving ecological inference by
modelling the source of zero observations." Ecology
Letters 8.11 (2005): 1235-1246.
informative. Thanks for sharing this
ReplyDeletenice article ,nice potting has great information.-best-hacks-to-boost-google-rankings . i have read it with keen interest and increased my knowledge. learnt that which i did not know before. thanks for sharing.
ReplyDeleteCoursework writing services
Do you wait until the last minute before undertaking tasks and assignments? Most people will procrastinate until they can wait no more and then rush to beat the deadline. When it comes to taxes, there are quite some pitfalls of taking this route.
ReplyDeletewrite my paper for cheap
This solution is no doubt, spending plan pleasant yet really effective that you can constantly utilize for promoting your organization as well as bringing direct exposure on international degree. buy real usa facebook likes
ReplyDeleteThe post is very nice. I just shared on my Facebook Account.
ReplyDeleteI am happy to find this post very useful for me, as it contains lot of information. I always prefer to read the quality content and this thing I found in you post. Thanks for sharing.
ReplyDeleteHow to interpret results from hurdle model
ReplyDeleteLink to dataset is dead
ReplyDeleteAnkara
ReplyDeleteBolu
Sakarya
Mersin
Malatya
J6PTKD
yozgat
ReplyDeletesivas
bayburt
van
uşak
TKCF
hatay evden eve nakliyat
ReplyDeleteısparta evden eve nakliyat
erzincan evden eve nakliyat
muğla evden eve nakliyat
karaman evden eve nakliyat
PKE2K
tekirdağ evden eve nakliyat
ReplyDeletekocaeli evden eve nakliyat
yozgat evden eve nakliyat
osmaniye evden eve nakliyat
amasya evden eve nakliyat
JMKF7R
F260F
ReplyDeleteElazığ Parça Eşya Taşıma
Hatay Parça Eşya Taşıma
Aksaray Lojistik
Adıyaman Parça Eşya Taşıma
Bingöl Parça Eşya Taşıma
8FC0F
ReplyDeleteÜnye Mutfak Dolabı
Batman Şehirler Arası Nakliyat
Yalova Şehirler Arası Nakliyat
Isparta Evden Eve Nakliyat
Antalya Evden Eve Nakliyat
Bitfinex Güvenilir mi
Çerkezköy Evden Eve Nakliyat
Erzurum Parça Eşya Taşıma
Pancakeswap Güvenilir mi
D727B
ReplyDeleteÇerkezköy Oto Lastik
Jns Coin Hangi Borsada
Siirt Evden Eve Nakliyat
Giresun Şehirler Arası Nakliyat
Urfa Parça Eşya Taşıma
Omlira Coin Hangi Borsada
Mardin Şehirler Arası Nakliyat
Urfa Evden Eve Nakliyat
Bursa Parça Eşya Taşıma
B0144
ReplyDeleteBolu Şehir İçi Nakliyat
İzmir Şehirler Arası Nakliyat
Eryaman Boya Ustası
Kucoin Güvenilir mi
Isparta Lojistik
Çorum Evden Eve Nakliyat
Karaman Lojistik
Çerkezköy Petek Temizleme
Bitcoin Kazanma
FE6BA
ReplyDeleteManisa Şehir İçi Nakliyat
Bilecik Evden Eve Nakliyat
Çerkezköy Mutfak Dolabı
Düzce Parça Eşya Taşıma
Ünye Çatı Ustası
Bartın Şehir İçi Nakliyat
Yobit Güvenilir mi
Siirt Şehirler Arası Nakliyat
Ağrı Lojistik
7BA05
ReplyDeleteKırklareli Lojistik
Tunceli Şehirler Arası Nakliyat
Amasya Evden Eve Nakliyat
Malatya Şehirler Arası Nakliyat
Silivri Boya Ustası
Kars Parça Eşya Taşıma
Elazığ Parça Eşya Taşıma
Çerkezköy Kurtarıcı
Manisa Şehir İçi Nakliyat
D036B
ReplyDeleteYalova Şehirler Arası Nakliyat
Sakarya Şehir İçi Nakliyat
Erzurum Şehir İçi Nakliyat
Ankara Asansör Tamiri
Bolu Şehirler Arası Nakliyat
Antep Parça Eşya Taşıma
Aydın Evden Eve Nakliyat
Sivas Lojistik
Kırşehir Parça Eşya Taşıma
6E6F8
ReplyDeleteAntalya Şehirler Arası Nakliyat
Siirt Evden Eve Nakliyat
Zonguldak Şehirler Arası Nakliyat
Çerkezköy Televizyon Tamircisi
Giresun Şehir İçi Nakliyat
Bitmart Güvenilir mi
Gümüşhane Evden Eve Nakliyat
Ordu Evden Eve Nakliyat
Çerkezköy Petek Temizleme
C8743
ReplyDeleteBatman Parça Eşya Taşıma
Bitlis Parça Eşya Taşıma
Bayburt Şehirler Arası Nakliyat
Aksaray Şehirler Arası Nakliyat
Elazığ Parça Eşya Taşıma
Vindax Güvenilir mi
Adıyaman Şehirler Arası Nakliyat
Kırşehir Şehir İçi Nakliyat
Elazığ Şehir İçi Nakliyat
68DE2
ReplyDeleteGümüşhane Evden Eve Nakliyat
Bursa Evden Eve Nakliyat
Eryaman Alkollü Mekanlar
Sinop Evden Eve Nakliyat
Ankara Parke Ustası
Bitrue Güvenilir mi
Antep Evden Eve Nakliyat
Etimesgut Fayans Ustası
Çerkezköy Oto Lastik
D4E53
ReplyDeleteDenizli Şehir İçi Nakliyat
Çerkezköy Halı Yıkama
Çerkezköy Ekspertiz
Çerkezköy Petek Temizleme
Bitget Güvenilir mi
Zonguldak Parça Eşya Taşıma
Hatay Evden Eve Nakliyat
Adıyaman Şehirler Arası Nakliyat
Batman Şehirler Arası Nakliyat
4B74E
ReplyDeleteArea Coin Hangi Borsada
Omlira Coin Hangi Borsada
Anc Coin Hangi Borsada
Ünye Petek Temizleme
Star Atlas Coin Hangi Borsada
Batıkent Fayans Ustası
Giresun Şehir İçi Nakliyat
Ünye Fayans Ustası
Karabük Lojistik
F2F15
ReplyDeletehttps://referanskodunedir.com.tr/
308D4
ReplyDeleteresimli magnet
referans kimliği nedir
binance referans kodu
referans kimliği nedir
resimli magnet
resimli magnet
binance referans kodu
binance referans kodu
binance referans kodu
07F02
ReplyDeletebinance referans kodu
resimli magnet
referans kimliği nedir
binance referans kodu
resimli magnet
binance referans kodu
binance referans kodu
referans kimliği nedir
resimli magnet
50169
ReplyDeletekadınlarla rastgele sohbet
zonguldak bedava görüntülü sohbet
rastgele sohbet uygulaması
ordu sesli sohbet sitesi
ağrı goruntulu sohbet
ucretsiz sohbet
giresun ücretsiz sohbet uygulaması
muş görüntülü sohbet sitesi
şırnak ücretsiz sohbet siteleri
DC493
ReplyDeletesohbet
Ordu Görüntülü Sohbet Siteleri Ücretsiz
aydın en iyi görüntülü sohbet uygulamaları
bayburt parasız sohbet
ardahan ücretsiz sohbet uygulaması
tunceli kadınlarla sohbet
kocaeli chat sohbet
seslı sohbet sıtelerı
diyarbakır bedava sohbet odaları
98FDF
ReplyDeleteParibu Borsası Güvenilir mi
Bulut Madenciliği Nedir
NWC Coin Hangi Borsada
Floki Coin Hangi Borsada
Tiktok Beğeni Satın Al
Sweat Coin Hangi Borsada
Paribu Borsası Güvenilir mi
Facebook Sayfa Beğeni Satın Al
Parasız Görüntülü Sohbet
6C513
ReplyDeleteCoin Kazma
Kripto Para Üretme Siteleri
Binance Hangi Ülkenin
Kripto Para Kazma
Binance Nasıl Üye Olunur
Bitcoin Nasıl Alınır
Bitcoin Oynama
Dxgm Coin Hangi Borsada
Görüntülü Sohbet
A4A4D
ReplyDeleteBinance Ne Zaman Kuruldu
Tiktok İzlenme Hilesi
Bitranium Coin Hangi Borsada
Parasız Görüntülü Sohbet
Threads Takipçi Hilesi
Discord Sunucu Üyesi Hilesi
Clubhouse Takipçi Hilesi
Youtube Abone Hilesi
Sonm Coin Hangi Borsada
AE676
ReplyDeleteBitcoin Kazanma
Onlyfans Beğeni Satın Al
Facebook Beğeni Hilesi
Aion Coin Hangi Borsada
Tumblr Takipçi Hilesi
Sonm Coin Hangi Borsada
Spotify Dinlenme Satın Al
Lovely Coin Hangi Borsada
Tumblr Beğeni Satın Al
5E258
ReplyDeletebingx
paribu
binance referans
canlı sohbet ücretsiz
bitcoin ne zaman yükselir
filtre kağıdı
rastgele canlı sohbet
referans kimligi nedir
bitget
79426
ReplyDeletekucoin
kraken
copy trade nedir
bybit
telegram kripto kanalları
filtre kağıdı
okex
kaldıraç nasıl yapılır
canlı sohbet odaları
ED674
ReplyDeletebitget
bybit
bybit
okex
kucoin
telegram kripto para kanalları
en güvenilir kripto borsası
bitcoin hangi bankalarda var
kraken
2D411
ReplyDeletekucoin
poloniex
bitmex
binance referans kod
binance
bitcoin nasıl kazanılır
bibox
copy trade nedir
kripto para haram mı
504A4
ReplyDelete----
----
----
----
matadorbet
----
----
----
----
97F6B
ReplyDelete----
----
----
----
matadorbet
----
----
----
----
0C5FE
ReplyDeleteehliyet sınav soruları
güneş paneli fiyatları
Sosyal Medya İş İlanları
Sosyal Medya Danışmanlığı
seo nedir
Tiktok SEO
Boştaki Domainler
Anime Önerileri
Facebook Reklam Verme
40471
ReplyDeleteİçerik Yazarı İş İlanları
kitap önerileri
anime önerileri
Bing SEO
Lisans Satışı
Eticaret SEO
4G Mobil Proxy Satın Al
freelance iş ilanları
Telegram Reklam Verme
88D74
ReplyDeleteYoutube SEO
Google Adwords Kupon Satışı & Alışı
Mobil Proxy Satın Al
Twitter Takipçi Satın Al
Facebook Takipçi Satın Al
bitcoin forum
İçerik Yazarı İş İlanları
Bilişim Hukuku
logo tasarım
E64C3
ReplyDeleteYoutube Abone
Online Oyunlar
Sosyal Medya İşleri
Tiktok Reklam Verme
smm panel
Toptan Ürünler
Knight Online Proxy
mmorpg
film önerileri
79693
ReplyDeleteOng Coin Yorum
Kda Coin Yorum
Doge Coin Yorum
Qtum Coin Yorum
Ach Coin Yorum
Rose Coin Yorum
1inch Coin Yorum
Knc Coin Yorum
Vite Coin Yorum
4E024
ReplyDeleteWaxp Coin Yorum
Nmr Coin Yorum
Mask Coin Yorum
Ape Coin Yorum
Iost Coin Yorum
Lazio Coin Yorum
Oxt Coin Yorum
Glm Coin Yorum
Bitcoin Son Dakika
dsgsdhbj
ReplyDeleteصيانة افران بمكه
مكافحة حشرات OnJizfZt7l
ReplyDelete1F0674551F
ReplyDeletegörüntülü show
şov
www.ijuntaxmedikal.store
cialis
steroid satın al
steroid satın al
رقم مصلحة المجاري بالاحساء vckk5ZuuKE
ReplyDeleteرقم مصلحة المجاري بالاحساء vfSkZ3JTug
ReplyDeleteA70627D2BA
ReplyDeletefake takipçi
tiktok beğeni satın al
fake takipçi
ig takipçi
yabancı takipçi